In my last post I wrote about attending a workshop where we debated whether it will ever be possible to “solve the brain”. I suggest you read that post before diving into this one. In this post I’ll summarize our discussions about what tools are needed in order to solve the brain and whether collecting more data is all it will take.
To recap, our debate topic was phrased as: “Give me a high-density optrode and a large-field microscope, and I will solve the brain.” Interpreted loosely, this prompt asked us to consider whether the ability to manipulate and record the activity of any cell in the brain would be sufficient to understand how it works.
What about molecules?
My first response is no, simply because those tools completely ignore the molecular mechanisms taking place within each brain cell. Molecular processes such as gene expression, protein transport, and synaptic vesicle release are critical for determining neuronal activity, which is the currency of the brain.
Moreover, many brain functions are in fact implemented at the molecular level. For example, various forms of learning and memory are mediated by molecular changes such as gene expression and receptor trafficking. By simply measuring neuronal activity you could observe the outcome of those changes, but you wouldn’t be able to discern the actual mechanism. Going back to Marr’s three levels of analysis, perhaps you’d achieve the second level (algorithm) but you’d certainly fail in understanding the third level (implementation).
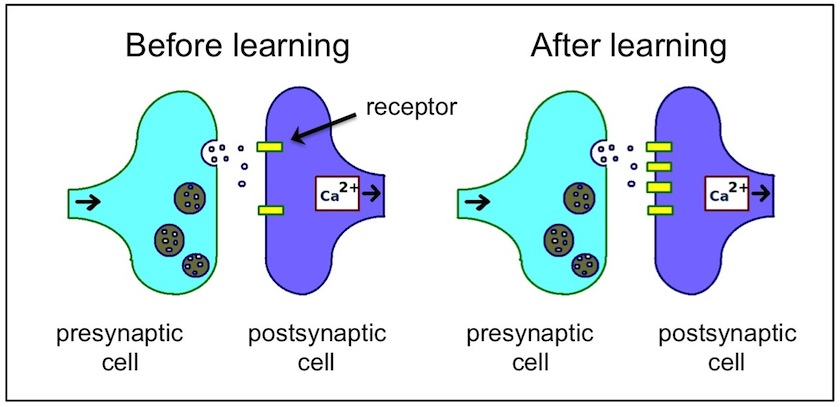
Many types of learning are mediated by an increase in the number of receptors at the synapse, which strengthens the communication between two brain cells. (credit: T. Sulcer via Wikimedia Commons, modified)
Molecular studies are particularly important in one area of neuroscience: studying disease and disorders of the nervous system. Genetic factors influence one’s susceptibility to nearly all neurological disorders, including Alzheimer’s disease, Parkinson’s disease, schizophrenia, addiction, and depression. To understand the link between genes and disease, we absolutely need molecular and genetic studies in additional to functional studies of neural activity.
We can’t read a mouse’s mind
Ok, so the tools given in the debate prompt are limited in their scope. But for the sake of argument, let’s say that we do have the ability to conduct any type of experiment known to neuroscience: molecular, genetic, developmental, anatomical, and biochemical studies, to name a few, along with the ability to manipulate and record neuronal activity. Are these all the tools we need?

credit: Craig Swanson
I’d say that our tools are still limited in at least one way: we lack the ability to study any functions of the brain that don’t produce an overt behavioral response. This is especially problematic in animal studies, which represent the vast majority of neuroscience. We can train a mouse to press a lever depending on what it sees or smells, we can test simple forms of learning, and we can even probe simple “emotional states”, such as being aroused or sleepy or stressed. But these studies barely scratch the surface of what the brain does. We can’t properly assess exactly what an animal is feeling or thinking.
You might say that the solution is to conduct all of our studies in humans, who can simply report what they’re feeling or thinking. But aside from all the technical and ethical complications inherent in human studies, relying on self-reported feelings is also limited; it’s not very quantitative and is subject to bias. Until we have more objective and quantitative paradigms for observing the mental states of humans or animals, there are some brain functions that are going to be inaccessible to scientific study.
Brains are machines
But again, let’s accept that limitation and move on. Maybe we won’t understand emotion anytime soon, but what about other behaviors and cognitive processes? Will the ability to manipulate and record every molecular or neuronal process in the brain lead to an understanding of how the brain works?
My first instinct at this point is to say yes. As I’ve written before, the brain is just a physical machine made of physical components. There’s no reason we shouldn’t be able to understand how it works once we have the ability to examine each of those components individually, in every context, and to determine how perturbing any one component affects all the others. But this is where my debate teammates opened my eyes to a couple of alternative views.
Fitting the data isn’t an explanation
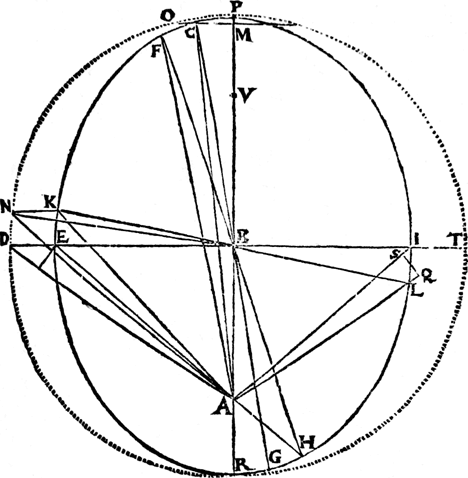
one of Kepler’s drawings of planetary motion (credit: NASA Earth Observatory)
First of all, it’s not clear that simply acquiring tons of data will lead to conceptual understanding. As a historical example, Johannes Kepler mined massive datasets obtained by Tycho Brahe and determined that planetary motion could best be described by ellipses. This model was an excellent fit to the data—it precisely predicted future planetary motion—but it didn’t provide any conceptual or intuitive understanding of the laws governing their motion. This solution awaited Isaac Newton.

Newton’s laws explain how planetary orbits are formed due to competition between a planet’s forward motion and the sun’s gravitational pull.
By considering the broader problem of objects moving in space and generating equations that covered all such cases, Newton was able to formulate more general models of motion and gravity, of which Kepler’s laws were special cases. Moreover, Newton’s model provided an intuitive explanation of why the planets travel in ellipses.
One could argue that collecting lots of data about the brain will allow us to predict behavioral outputs from neural activity or vice versa, but this level of understanding is analogous to Kepler, not Newton. This would be a description of the data without the conceptual understanding. To channel Newton we need more than just data; we need to generate the right theories and models.
Could a neuroscientist understand a microprocessor?
My teammates also made a second argument for why more data alone may not be sufficient to understand the brain. This argument again harkens back to artificial networks.
In a recent paper by Jonas and Kording, the authors ask whether modern neuroscience approaches would be sufficient to understand a simple microprocessor. They take a microprocessor from the Atari video game system as their “model organism”. The microprocessor is similar to the brain in several ways. For example: it consists of individual elements (transistors) connected in a specific pattern; the activity state of each transistor affects the transistors it is connected to; it contains specialized modules organized hierarchically.
We know how this microprocessor works because the designers laid out their plans: you can see different modules that perform different functions. The question is, without these plans, could you figure out how the microprocessor works using the same approaches that are being used to study the brain?

The microprocessor’s design is known to us (though likely inscrutable to those of us who aren’t engineers), and different parts carry out different functions. (from Jonas and Kording, 2016)
In the paper, Jonas and Kording simulate “experiments” such as deleting each individual transistor, recording the activity of each transistor at each time, correlating the activity of different transistors, and analyzing global activity dynamics. Their conclusion: none of these experiments revealed any significant insight into how the microprocessor works.
Upon reading this paper a couple weeks ago, I fell into a deep despair and was ready to concede that neuroscience, my passion and career, is in fact a hopeless enterprise. Fortunately that state didn’t last long, and I became less convinced that the methods in the paper are the only methods available to neuroscientists studying the brain.
In my view, the main limitation of the paper is that the authors tried to understand the whole microprocessor at once. Instead, I would advocate a more focused approach. For example, take one transistor that seems to be particularly interesting or important based on its connectivity or activity. Identify all its inputs and outputs and determine how it is affected by each input and how it affects each output. This should give you some insight into how it processes information. Then gradually expand this analysis to the transistors it’s connected to. It seems to me that you’d eventually uncover some of the functional modules depicted in the design plan.
The authors themselves point out that the real limitation of their approach was a lack of hypotheses. They concede that if you had specific hypotheses about how the system works then they would be reasonably easy to test, but claim that the number of potential models is “unbelievably large”.
This is certainly true, but in neuroscience our hypotheses are constrained by what we already know. In most brain regions we have some knowledge of how the neurons are connected and what their activity patterns look like, and these data lead us to favor certain hypotheses over others. This is why I’m not quite so pessimistic about the ability of modern tools to understand the brain.
Consensus?
Ultimately, the debate seemed to end on a relatively optimistic note. We know that fancy tools will be necessary to solve the brain, but no one thinks they’ll be sufficient. We also need intelligent and creative people from different backgrounds and perspectives to channel Newton and put forth theories and models of how the brain works. We need people to test those hypotheses by collecting lots of data, and we need people to make new models when some of our ideas inevitably turn out to be wrong.
Fortunately, I think we neuroscientists are up to this challenge.